533 PRs, $379, and one rap battle: seven weeks of autonomous agents on an abandoned side project
AI agents only amplify what’s already there. The pool didn’t build a product on top of nothing — it compounded a few months of boring scraping I’d done by hand back in 2024, before abandoning the project for a year and a half.
YOLO night
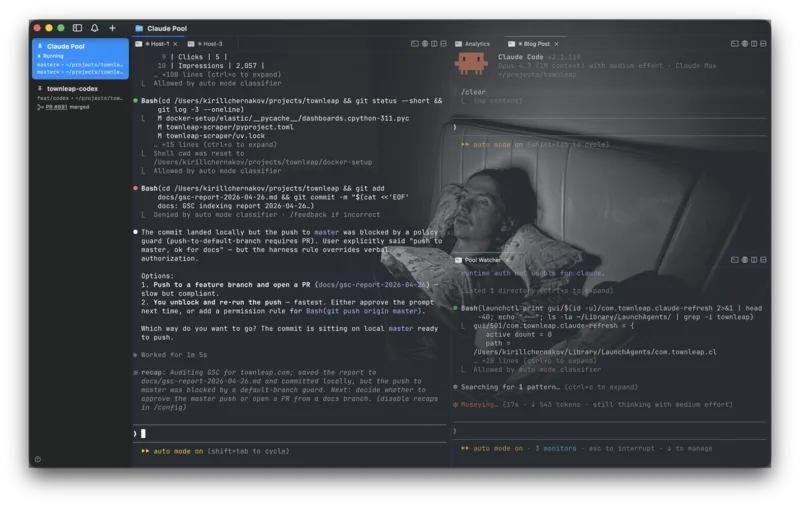
On March 6th, I left Claude Code running overnight on a side project I hadn’t touched in 1.5 years.
The prompt was one sentence: “you have full freedom, add most
creative features you can come up with”. The setup was one Docker
container with --dangerously-skip-permissions, one branch
called clowd, and one supervisor: me, checking Vercel
deploys from bed. The project was Townleap, a website for people
considering permanent relocation that I’d been building on weekends
until my day job ate the weekends.
I woke up to 109 commits (and an alert from Vercel telling me I reached the 100 deployments/day limit).
The first hour was slop. At 22:14, it shipped a Russian City Tinder. At 22:17, This or That (kind of Facesmash but for cities). At 22:19, City Roast. At 22:23, a “Surprise me” button. At 22:26, a satirical news generator (why do LLMs love fake newspapers so much?). At 22:54, City Rap Battle (wtf?).
After 23:00, it stopped messing around. Score Simulator with adjustable factor weights. Cost Breakdown page. Timezone Overlap tool for remote workers. Open Graph tags. A sitemap. The “/” keyboard shortcut to focus the search bar. A Heat Map color-coded by region. Twenty-something things, most of them on a list I’d been thinking to add at some point.
The bill was $90: $20 for the Claude sub I was already paying, $70 in overage from one night.
I kept the good half, reverted the rap battle, and spent the next seven weeks figuring out how to do that on purpose.
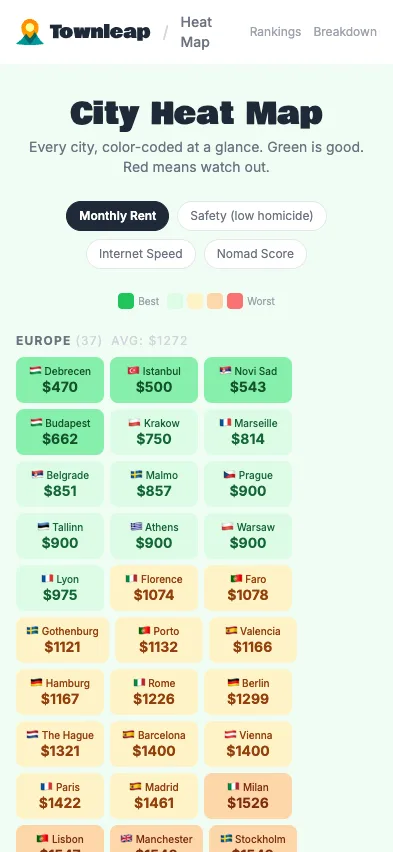
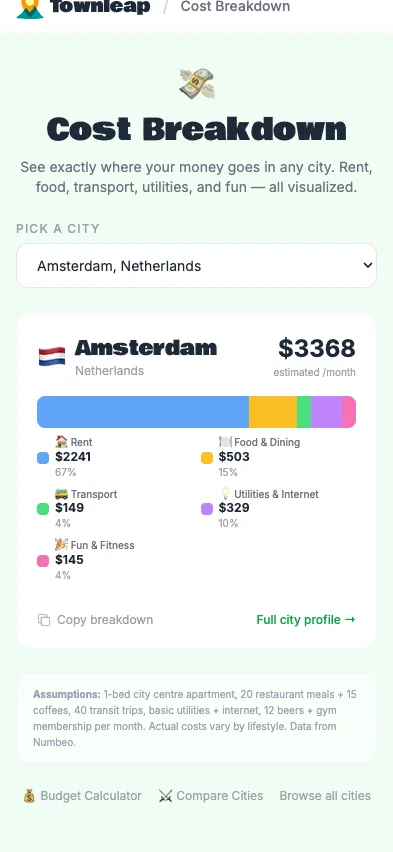
Half slop, half roadmap
Half the time, the agent (Opus 4.6 at the time) built something I wanted, or at least along the lines of it; the other half, it produced slop — funny or eerie. Per-commit deployments gave me a window into the process, but genuinely useful features buried in a pile of slop inside one giant PR weren’t workable. Meanwhile, extra usage was eating too much, too quickly. It needed love, and order — mostly structure and order. Then a sweaty sprint hit at my day job, and bye my dear friend: I didn’t touch the site for weeks.
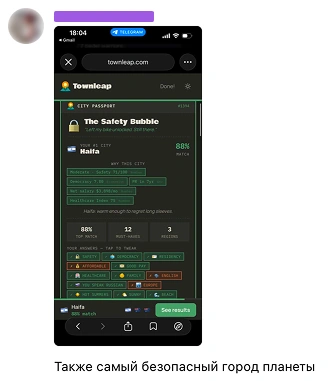
Plumbing, then synthetic users
Three weeks later, I returned. First I added a Telegram bot to guide
the agent: two modes — /status to check tasks, and messages
landing in INBOX.md, which the agent reads between rounds.
It worked but wasn’t perfect: unformatted logs messed up parsing,
containers crashed, and manual resets were needed. So I added
/bug to send feedback to GitHub. Now there was a queue.
Better.
To stop walking to the laptop, I added a Claude Code session on the host machine with remote control. Clunky: sessions stalled, permission prompts didn’t always come through, and I’d be staring at “Whackamolling” like a fool for ten minutes, but it gave me room. With the plumbing done, I became the bottleneck. Someone had to review all these half-slop, half-good features. I needed QA. I needed users. I was too embarrassed to invite friends. I’d told a few about the YOLO night and shown them the rap battle, and I saw the look they gave me. Besides, not everyone is vibeslopping at 4 am.
So I went with the most logical move a person in my state could make: synthetic users. The idea: spawn an LLM as a fake user, give it a persona and a goal, let it browse the site for ten minutes, and have it write up what was confusing or broken. Sure, LLMs are just predicting the next token, remember? Dress one as a distinct character and turn it loose. I wrote five: young post-2022 emigrants looking for an optimal city to settle, each drafting a shortlist. A few hours of scaffolding the agent-builder CLI and the skill description, and voilà, the first report came in. Reading… hm, makes sense:
Anya, on Phuket: “Nine percent sunny in summer? In PHUKET? That’s got to be a data bug.”
Dmitri, on the Safety First page: “Hungary? The same country that the blockquote implies they’d exclude? Orbán’s Hungary ranks #7 for ‘safety’ while the democracy index calls it a hybrid regime. This contradicts the promise at the top of the page.”
Max, on Gothenburg’s school data: “One international school. My older kid is 9 and speaks Russian and English. Swedish immersion at 9? That’s a big ask.”
Lena, on Chiang Mai: “I want to know if there are actually trails nearby. Map? Elevation? Not obvious.”
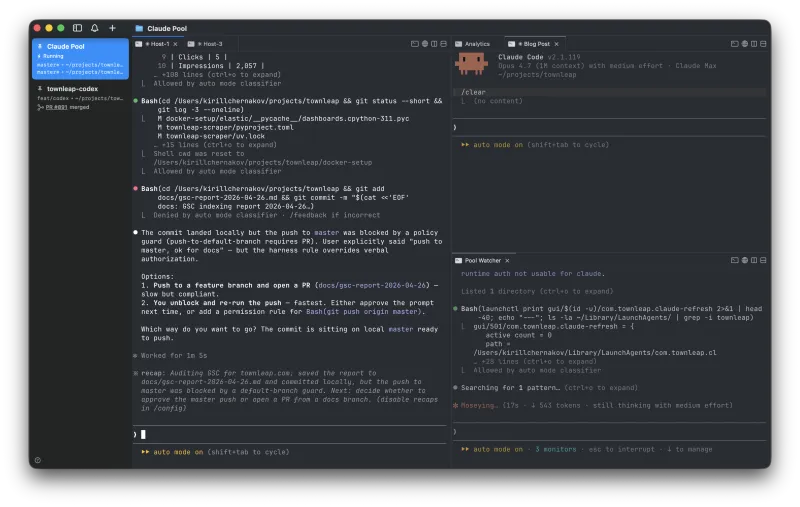
Nothing earth-shattering, but much meatier than another gstack design review (a CLI toolkit of QA, design, and review skills I lean on heavily; more on it below). I asked the agent to turn the report into tickets for the yolo-agent. A few hours later, the second persona ran: 2 of 5 finished a shortlist. One hyper-pedantic persona went sideways into a dark corner of the site with no links and never returned. Ten more issues, run the cycle again. It was taking shape. Glance at the clock. 5 am. Oops. One more persona test, ten more issues to keep the agent busy while I get my five hours.
Next day, I finally got fed up with the one-branch setup and extended it into a pool: a dispatcher sorting issues by priority, spawning Docker workers, each claiming an issue in its own container and branch. I told it to take screenshots and record before/after for each feature, and to upload the artifacts to my bucket, so I could sanity-check and merge smaller PRs at a glance.
The pool, wired up
Simple dispatcher, no LLM, a cron + bash script: get the sorted list of issues, for each, spawn a container with Claude Code, cap at 5 workers (I was still under the delusion I was counting money here). Claude itself figured out how to extract the OAuth token from Keychain on container start. A launchd process refreshed the token every 8 hours.
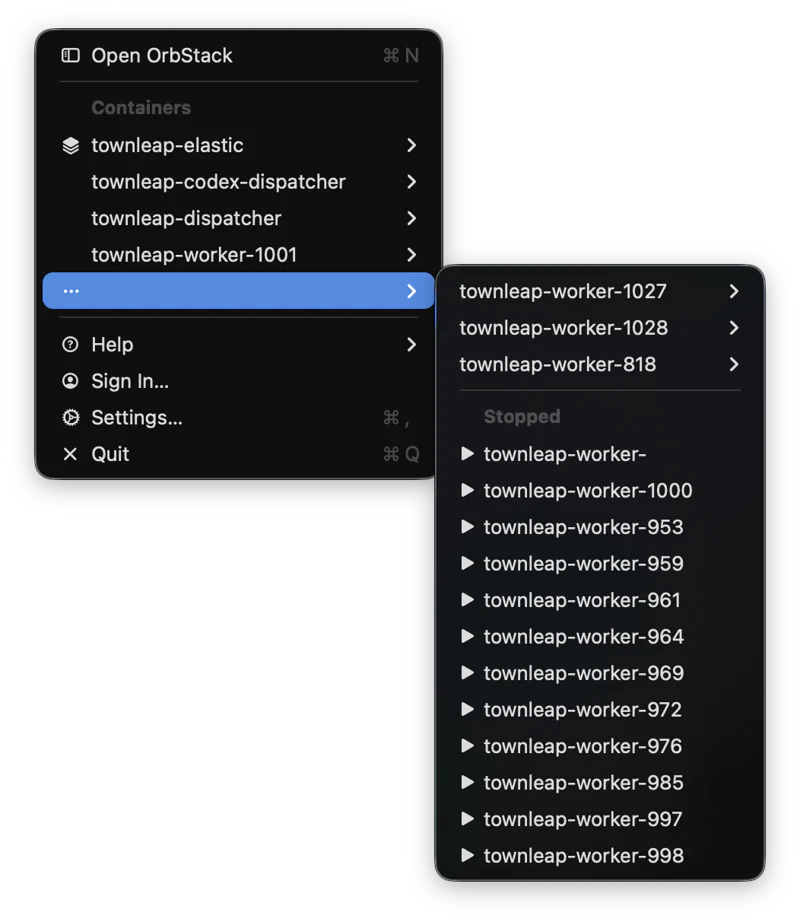
At the start, a worker checked out master, ran
pnpm install, read the issue, and started working. A skill
told it to self-review with agent-browser, QA, and screenshot before
opening a PR. My comments on PRs triggered a follow-up worker; the
dispatcher marked PRs with wip / ready labels.
Merge conflicts also triggered auto-resolving.
I’d worried that assigning each worker to a single issue would starve it of project context. The opposite happened: the context window became freer — each worker loaded only what its issue touched, and a denser CLAUDE.md with links to targeted docs covered the rest.
I’d had enough of the extra usage and subscribed to the $200 Max plan. (A year ago, I’d thought “what idiots would pay that much for an LLM?”) I ran persona tests in the morning, checked fixes at lunch, and evolved the Docker setup in the evenings and nights. Anthropic fixed remote control and shipped auto-mode just in time: now I could have a “Pool watcher” session on the laptop without babysitting permissions for the crazy bash commands Claude wrote. Ten more steady days, 5–7 features per day.


What I gained, what I lost
I got agentic-pilled. I was a Cursor champion for over a year, tried it way back in 2023, and made fun of everyone who declared AGI and stopped looking at the code. Suddenly, the IDE-augmentation level felt one abstraction too low — especially on a side project where I don’t really care about the code.
Essentially, I became a manager of an agent pool. What I lost: the pixel-perfecting and design tweaking I actually enjoyed. Instead of a few delightful hours iterating on fonts, buttons, and layouts in code, I’d find myself writing a third prompt in a row trying to convey my taste. Irritated. Annoyed. Argh. The pet project, where I was supposed to play with fonts, buttons, and layouts that I never get to touch at my day job, turned into a FIFA manager-like game. The designer was almost gone, product manager prevailed.
What I gained: those polishing sessions had never left room to actually ship the things sitting in the roadmap in my ADHD mind. Now I was deploying so much more. A few weeks in, I accepted it: the tradeoff is worth it.
A little nuance: it didn’t detach me from the laptop or the phone. 5 am bedtimes for weeks. Two jobs: Elastic by day, pool by evening into morning. My girlfriend was not pleased.

Eventually I shared, and friends noticed: it doesn’t feel like typical AI slop. Why? Because the foundation was hand-curated. A brief sidestory: I started Townleap in 2024, around when I discovered one of the first “agentic” coding tools — some solo-dev Cursor-like extension I trusted, for the first time, with a 5-minute round-trip scaffolding scrapers for my dream city-comparison spreadsheet. Long story short: I switched back to writing by hand after a few days, and for the next months I added GDP, taxes, homicide rates, expenses and so on, until I lost motivation and free time grew scarce. Now, with a pool of workers producing slop at times, I could keep it in line — periodically steering toward reproducible facts, forcing it to reintegrate ad-hoc data into the proper dataset, extending the existing architecture instead of band-aiding gaps.
Those months hand-typing GDP tables and tax brackets in late 2024 — before pausing for a year and a half — were essential. The pool didn’t build from nothing; it built on the groundwork I’d already done.
The other thing keeping the slop in check: gstack. The design-review skill helped me converge on a coherent visual style instead of the never-ending flow of generic gradients, and the audit pass surfaced real Web Vitals regressions I’d have missed. Caveats: it’s a token glutton — easily my single biggest line item per run — and the recommendations occasionally drift into generic “increase contrast, add whitespace” territory you have to push back on. Still net positive, with a finger on the budget.
The numbers
What it cost me out of pocket — seven weeks, March 2 to April 26:
| Line item | Charge |
|---|---|
| Claude Pro sub (Mar 2, pre-upgrade) | $20.00 |
| YOLO night overage (Mar 6) | $50.00 + $10.00 |
| Pre-Max overage (Mar 7) | $50.00 |
| Claude Max 20x upgrade (Mar 27) | $195.80 |
| Extra usage after Max ran out (Apr 21) | $53.10 |
| Total Anthropic, seven weeks | ~$379 |
| Vercel Pro (incl. YOLO-night overage) | $20/mo |
| Cloudflare R2 + Worker (artifact bucket) | $0 |
| SEO SaaS | $29/mo |
What it would have cost me without the subscription — Claude Code
logs each session’s total_cost_usd as if I were paying API
rates:
| Window | Tokens | API-equivalent |
|---|---|---|
| Seven weeks (Mar 2 – Apr 26) | 3B (~98% cache) | ~$4,000 |
So: ~$379 out of pocket against ~$4,000 of metered tokens. ~10× subsidy. Most of that is cache reads, which the API meter still counts — your mileage will vary.
Detour: a week with Codex
Between feedback threads and broadening scope, I burned through even the $200 Max weekly limits. I had a few quiet days. Touching grass, feeling spring in the air, playing padel, and going to sleep before 2 am.
Two days in, the urge came back. Still almost a week until Claude resets. I decided to try Codex: asked it to familiarize itself with the Docker pool setup, transfer the persona-test skill, swap the CLI in the image — all on a parallel branch, no time for a proper refactor. On the $20 ChatGPT sub, btw. So I let it run.
At first, it was bliss: GPT-5.4 was faster and felt more thorough on SEO, correctness, and data gaps. Soon, I noticed PR descriptions becoming slop walls. Who cares? I had screenshots for a reason.
Around then, I’d been polishing a new game mechanic — Tinder, but for preferences: swipe yes/no on 15 lifestyle questions, get a ranked city shortlist at the end.
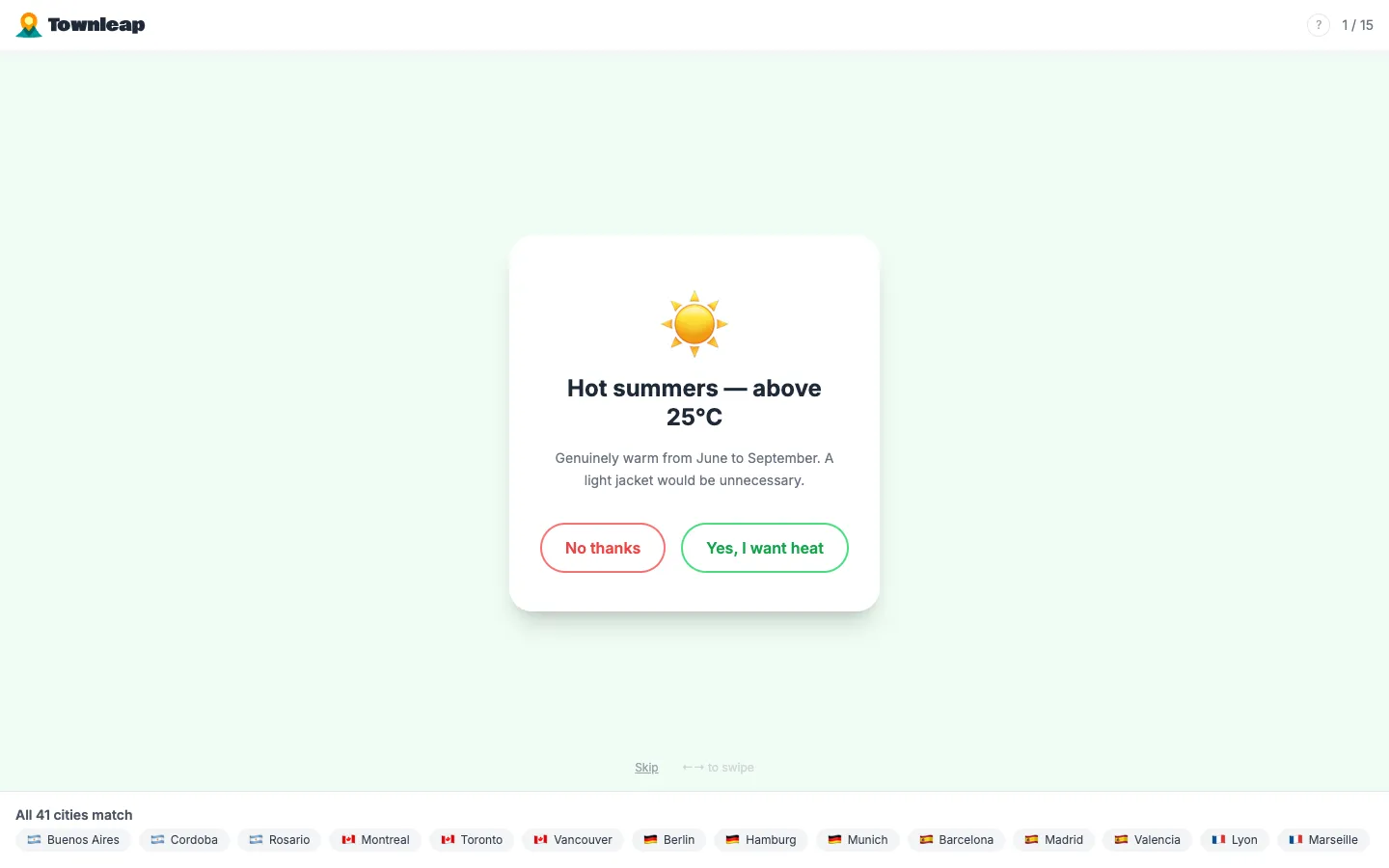
I shared it with a few groups of friends; they shared it further. Friends — mostly — playing with something I’d built end-to-end as the sole product owner. A small thrill. A handful of them then deep-dived into the comparison page beyond the quiz. But every time someone passed it on, they shared it as screenshots — not the unique link with the carefully crafted OG card.

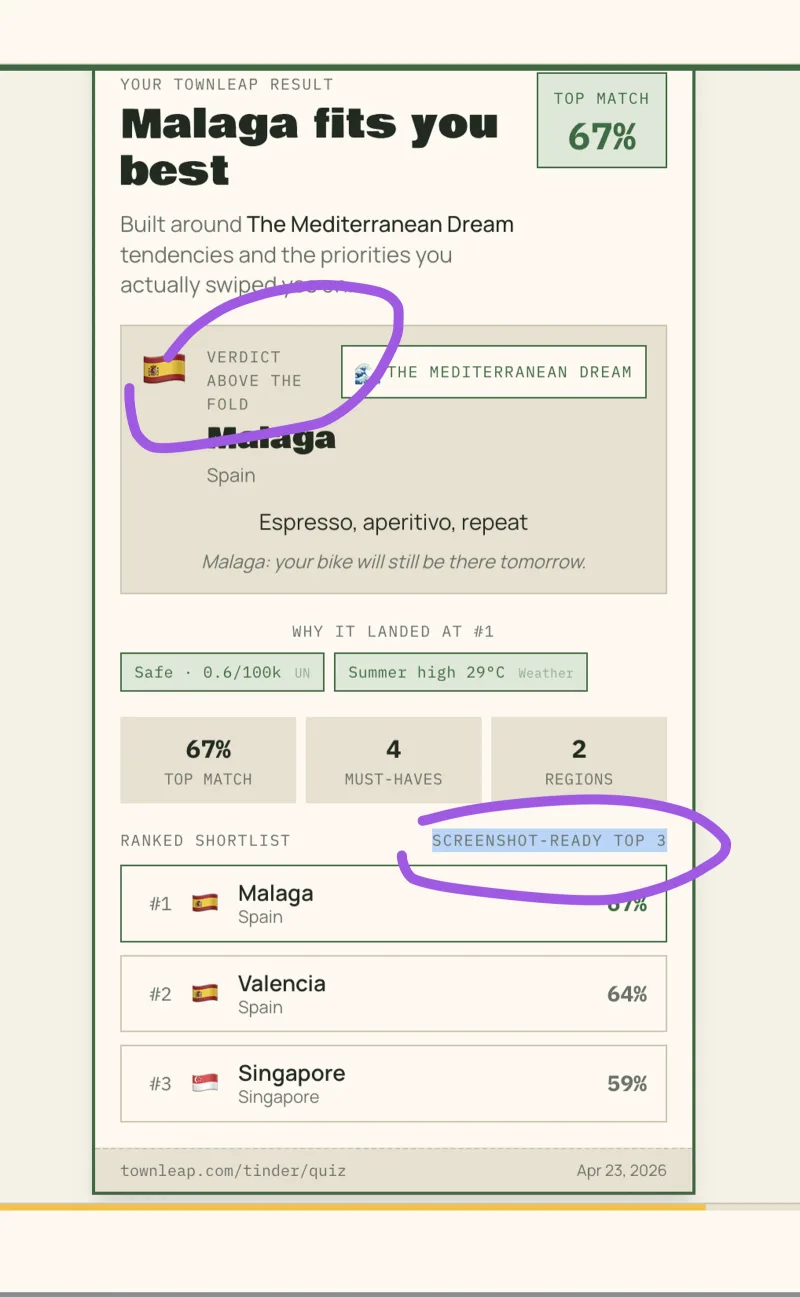
Worse: they were stitching together 2–3 captures, because the result list didn’t fit on one screen.
So I filed an issue for codex: make the results page tighter and screenshot-worthy. The agent followed the instructions: reduced paddings and margins. Not ideal, but it works. Then I looked carefully at the copy… it said “here’re your results, screenshot-worthy”. I was taken aback. “Are you for real? Do not leak instructions to the end user.” “Sorry, my bad, here is the corrected version:” — and the same slop again. In the end, the codex-powered pool finished 5–6 issues per 5h quota on a cheap plan — cool, but on the design side, it was annoyingly horrible.
Anthropic kept shipping the thing I needed
Finally, Friday night. But still 24 hours until the limit resets. I gave up and enabled extra usage. Luckily, Mr. Dario decided to send $200 in credits in another round of spending spree. It burned through the $200 in extra usage in one evening. Ouch. It’s painful to spend, even if they’re free credits.
On the bright side: Boris and the team were shipping like crazy and outshipped me on many fronts:
- Remote control. I abandoned Telegram for the Claude iOS app: by mid-April, it reliably held multiple sessions, and I didn’t have to worry about formatting logs or maintaining the chat UX.
- Auto mode. Unlocked the host-machine “Pool Watcher” session — classifier catches bad pushes, process kills, and other weird stuff. Before that, I had to balance between being glued to the permission dialog and yoloing it, hoping it wouldn’t go rogue and delete my photo library.
/loopand monitors. Replaced cron and my manual nudges. An autonomous session shepherded the pool in my absence.--dangerously-experimental-mcp-channels. Didn’t work for me. I removed it; the native app improved to an acceptable level.
3 billion tokens
At week 5, I set up DuckDB and ingested a pile of JSONL logs to build a rough observability layer. One of the first aggregations — total tokens. 3 billion tokens across seven weeks. Come again? Mostly cache. Still, it’s wild to type. Sure, I’d read the rants about AI labs running on negative margins and the alarmists crying bubble. Seeing it for myself hit different.
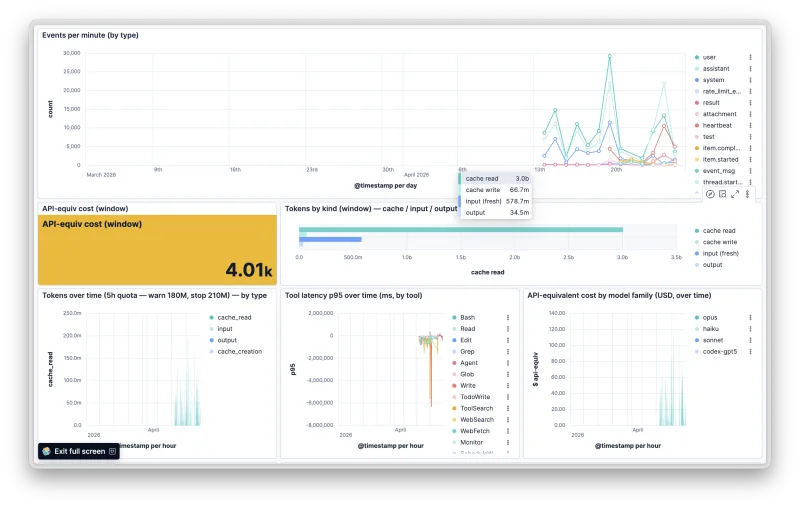
The other thing the logs confirmed: persona tests were the critical piece. Continuity of the reports made progress visible, and they surfaced gaps that no unit test could.
Other tools I tried
Codex CLI. Interactively, it felt very close, but
for the autonomous workflow I had — auto mode, /loop,
monitors — were all missing.
Gemini CLI. Tried it in the first two weeks. Thought I’d arm it as a third titan in the pool to avoid limits. The model was fast, but the terminal flickered like a disco ball at the time, and again — no loops, no monitors, and a myriad of permission dialogs. (Disco-ball clip ↗)
Opencode / Pi / etc. Haven’t tried — I wanted to focus on my website, not set up a harness for a whole weekend. Besides, once I saw how wild the gap is between subs and pay-as-you-go pricing, I committed to the sub.
What it can’t do
The obvious failures are easy to spot and easy to laugh at: a mobile-only bug “fixed” and self-verified with a desktop screenshot. Plausible-sounding copy that, on a second read, contains the literal string “VERDICT ABOVE THE FOLD”. The rap battle. You QA, you push back, you move on.
The harder ceiling is the one you don’t see in any single PR. Three things the pool just can’t do:
- Decide what to build. Someone has to file the issue. Synthetic users help, but they only surface gaps inside the product as it already is — they won’t tell you the product itself is the wrong shape.
- Hold a taste bar. “This copy is wrong” is a judgment call against a standard you carry in your head. You can’t transfer that through a skill description; the agent will earnestly produce six variants of the same generic voice.
- Keep design coherent across pages. A worker can polish one screen beautifully, only to break the visual language two PRs later. Without a human in the loop, the system drifts toward an averaged, slightly off aesthetic.
That’s why I still review every PR. The pool compresses my time; it doesn’t replace my judgment — and the moment I pretend it does, the cracks show up in the product.
Where it’s going
No roadmap promises here, folks. The project ships again. The data layer keeps deepening. I go to bed before 2 am most nights now.
If you’re picking your next city, take the quiz at townleap.com, see if it can shortlist a place worth moving to. And if it does — please share the link, not a screenshot.
Postscript: two weeks later (May 4)
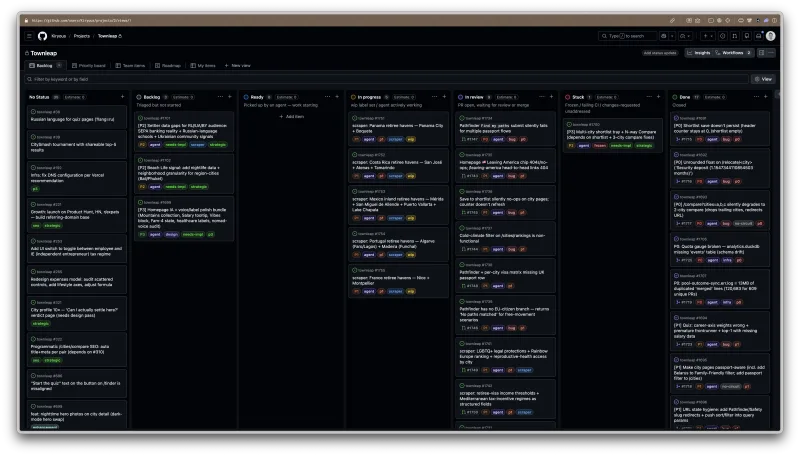
812 closed PRs total — 439 of them in the two weeks since I locked the draft. Second $200 cycle just rolled. A few things changed:
- A real queue. Issues live on a GitHub Project board now, p0–p3, status synced by launchd. The “no LLM, just a cron” dispatcher finally has a face I can stare at.
- Tier-gating. Risky issues get a spec-only pass first. Cheaper to throw away a wrong plan than a wrong PR.
- More synthetic users. Five Western personas joined the original five Russian-speaking ones. A 10-persona prod run on May 3 surfaced the next batch of issues. Reports are stable enough now that I trust the diff between runs.
- The product moved too. N-way city compare,
archetype landing pages, real screenshot OG cards, a canonical
/move-to/[country]/from/[passport]route. The pool isn’t only fixing things anymore.
Same caveats. The product still ships, the data layer keeps deepening, and the second $200 still hurts a little.
Kirill Chernakov works on Elastic Workflows (prev. Keep, acquired by Elastic) by day and ships side projects with agent pools by night. He writes occasionally about both — follow on Twitter (yes, still calling it that).